IT��Ӗ�W![]()
![]()

 Java��Ӗ
Java��Ӗ
 ܛ���yԇ��Ӗ
ܛ���yԇ��Ӗ
 Web��Ӗ
Web��Ӗ
 Linux��Ӗ
Linux��Ӗ
 Python��Ӗ
Python��Ӗ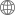
 ���W�I�N��Ӗ
���W�I�N��Ӗ
 UI��Ӗ
UI��Ӗ
 ����Ӗ
����ӖIT�ھ��W��![]()
![]()
���T�n�� ���� >


�Pע�҂�
 �ߴa�I�Y�� ����A�WIT
�ߴa�I�Y�� ����A�WIT  �Œߴa�Pע �؏�“��Y��”������
�Œߴa�Pע �؏�“��Y��”������ IT��Ӗ�W![]()
![]()
IT�ھ��W��![]()
![]()
�ߴa�I�Y�� ����A�WIT �Œߴa�Pע �؏�“��Y��”������ ���r�����S�����Ҫ���������Ĕ�����������IT�ИI(y��)����ô�������̎���Ҫ������Щ�أ����¾���һЩ����ԇ�}��

1����ô��Qkafka�Ĕ����Gʧ
2��fsimage��edit�ą^(q��)�e?
3�����e�ׂ������ļ���(y��u)��?
4��datanode �״μ��� cluster �ĕr����� log ��治�����ļ��汾������Ҫnamenode ��(zh��)�и�ʽ���������@��̎����ԭ����?
5��MapReduce ������l(f��)�����Ďׂ��A��?�@Щ�����Ƿ���Ա���?��ʲô?
6��hadoop�ă�(y��u)��?
7���ɼ�nginx�a������־����־�ĸ�ʽ��user ip time url htmlId ÿ��a�����ļ��Ĕ������σ|�l��Ո�OӋ�����є������浽HDFS�ϣ����ṩһ���r��ԃ�Ĺ���(푑��r�gС��3s)
8���� 10 ���ļ���ÿ���ļ� 1G��ÿ���ļ���ÿһ�д�ŵĶ����Ñ��� query��ÿ���ļ���query �������؏͡�Ҫ���㰴�� query ���l������ ߀�ǵ��͵� TOP K �㷨��
9���� 2.5 �|���������ҳ����؏͵�������ע���ȴ治�����ݼ{�@ 2.5 �|��������
10���vӍ��ԇ�}���o 40 �|�����؏͵� unsigned int ���������]���^��ģ�Ȼ���ٽoһ��������ο����Д��@�����Ƿ����� 40 �|��������?
���P���]��
��������
>>���ĵ�ַ��http://www.jecan.cn/jiuye/2019/47376.html
��:��վ����������й�������(y��u)�͘I(y��)���У�δ���S�ɲ��������D�d��





1 �������g
2 ���ČW�v
3 �������������������
 ��ǰ��
��ǰ�� ��
�� ���W�I�N
���W�I�N Java
Java Linux
Linux Python
Python Ƕ��ʽ
Ƕ��ʽ ȫ������\�I
ȫ������\�I ܛ���yԇ
ܛ���yԇ �҃��OӋ
�҃��OӋ ƽ���OӋ
ƽ���OӋ ����OӋ
����OӋ �W��OӋ
�W��OӋ UI�OӋ
UI�OӋ VR/AR
VR/AR �W�j��ȫ
�W�j��ȫ ��ý�w
��ý�w ֱ����؛
ֱ����؛ ���ܙC����
���ܙC����Copyright©1999-
�����й������Ƽ�����˾ .All Rights Reserved
��ICP��10218183̖-88
��ICP�C161188̖
 �����W����11010802020723̖
�����W����11010802020723̖
 Ͷ�V���h��400-650-7353
Ͷ�V���h��400-650-7353






