��һ�������Z(y��)��
�҂���Ҫһ���ľ����Z(y��)�Ի��A(ch��)����ҿ����ȌW(xu��)��(x��)Java��Pathon�����]��ҌW(xu��)��(x��)Java����?y��n)�Java�ѽ�(j��ng)����20�����ˣ��������ڏV��ʹ���С�
�������Java�Ļ��A(ch��)���Ϳ���ֱ�Ӳ���ڶ��A�ΌW(xu��)��(x��)�ˡ�
�ڶ���Linux����ϵ�y(t��ng)
��(sh��)��(j��)�(xi��ng)Ŀ��KҪ����Ⱥ�\(y��n)�У�����Ⱥ�IJ�����Ȼ�x���_(k��i)Linux����ϵ�y(t��ng)���W(xu��)��(x��)�A�Σ��҂�ͨ����(hu��)��̓�M�C(j��)���M(j��n)�Мy(c��)ԇ�������҂���Ҫ����̓�M�C(j��)�İ��b���á�����(l��i)����Linux���õIJ��������ˡ�
������Hadoop
�@��������˃ɉK��(n��i)�ݣ�һ��(g��)��HDFS���ֲ�ʽ�ļ�ϵ�y(t��ng)���҂���Ҫ����Hadoop��Ⱥ�Ĵ���Լ�HDFS API��ʹ�á���һ��(g��)����MapReduce��MapReduce��(sh��)�F(xi��n)��(sh��)��(j��)���x��Ӌ(j��)�㡣�҂�Ҫ����MapReduce�ľ���ģʽ�����Ͱ���������҂��x��Ӌ(j��)�����Spark��(sh��)�F(xi��n)����ô�@һ�A�ο������c(di��n)����HDFS��
���ģ�Zookeeper
Zookeeper����һ��(g��)�_(k��i)Դ�ķֲ�ʽ����(w��)��ܣ��ںܶ�ط�����������Ӱ���o(w��)Փ����Hadoop��Ⱥ�ĸ߿��ã�߀�Ǻ����Kafka�У�Zookeeper���DZ��^��Ҫ�ġ�
���壬Hive
Hive�ǻ���Hadoop��һ��(g��)��(sh��)��(j��)�}(c��ng)��(k��)���ߣ����Ԍ��Y(ji��)��(g��u)���Ĕ�(sh��)��(j��)�ļ�ӳ���һ���������ṩ�(l��i)SQL��ԃ(x��n)���ܡ�����Facebook�_(k��i)Դ�����ڽ�Q�����Y(ji��)��(g��u)����־�Ĕ�(sh��)��(j��)�y(t��ng)Ӌ(j��)��
��(j��)�W(xu��)��(x��)��Ҫ��Щ�n�̣�")
������HBase
Apache HBase��һ��(g��)�_(k��i)Դ��NoSQL��(sh��)��(j��)��(k��)���ṩ��(du��)���͔�(sh��)��(j��)���Č�(sh��)�r(sh��)�x/��(xi��)�L��(w��n)��
HBase���ԔU(ku��)չʹ�����܉�̎�����Д�(sh��)ʮ�|�к͔�(sh��)���f(w��n)�еĴ��͔�(sh��)��(j��)����
���ߣ�Kafka
Kafka��һ�N�ֲ�ʽ�l(f��)��-ӆ���Ϣϵ�y(t��ng)���������LinkedIn��˾�_(k��i)�l(f��)��֮��ɞ�Apache�(xi��ng)Ŀ��һ���֡������S�Ñ�(h��)�M(j��n)��ӆ醲�����(sh��)��(j��)�l(f��)�������┵(sh��)����ϵ�y(t��ng)��?q��)��r(sh��)��(y��ng)�ó����С�
�ڰˣ�Scala
Scala��һ�N�ʽ�ľ����Z(y��)�ԣ�����������?q��)��̺ͺ��?sh��)ʽ������һ����Scala�\(y��n)����Java̓�M�C(j��)�ϣ����Ժ�Java����o(w��)�p�쾎�������{(di��o)�á�
�ھţ�Spark
Spark�ĺ��IJ��������K��Spark Core ��Spark SQL��Spark Streaming��Spark Core������A(ch��)������ĵIJ��֣��@�����кܶ������(��ҿ���������鷽����(sh��))�������@Щ���ӣ����Է����ݵ��M(j��n)���x��Ӌ(j��)�㡣Spark SQL������ʹ���(l��i)sql�Z(y��)��̎���Y(ji��)��(g��u)����(sh��)��(j��)��Spark Streaming�t�Á�(l��i)̎�팍(sh��)�r(sh��)��(sh��)��(j��)��

 Java��Ӗ(x��n)
Java��Ӗ(x��n)
 ܛ���y(c��)ԇ��Ӗ(x��n)
ܛ���y(c��)ԇ��Ӗ(x��n)
 Web��Ӗ(x��n)
Web��Ӗ(x��n)
 Linux��Ӗ(x��n)
Linux��Ӗ(x��n)
 Python��Ӗ(x��n)
Python��Ӗ(x��n)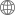
 ��(li��n)�W(w��ng)�I(y��ng)�N(xi��o)��Ӗ(x��n)
��(li��n)�W(w��ng)�I(y��ng)�N(xi��o)��Ӗ(x��n)
 UI��Ӗ(x��n)
UI��Ӗ(x��n)
 ��(sh��)��(j��)��Ӗ(x��n)
��(sh��)��(j��)��Ӗ(x��n) �ٷ�����̖(h��o) �؏�(f��)"��Y��"������
�ٷ�����̖(h��o) �؏�(f��)"��Y��"������  �I(l��ng)�W(xu��)��(x��)�Y�� ����IT֪�R(sh��)
�I(l��ng)�W(xu��)��(x��)�Y�� ����IT֪�R(sh��) 


























 �����W(w��ng)����11010802020723̖(h��o)
�����W(w��ng)����11010802020723̖(h��o)





